BI : Introduction à l’informatique décisionnelle
1. Qu’est ce que l’informatique décisionnelle ou BI ?
1. Constat général
Les entreprises utilisent une myriade d’applications et d’outils pour gérer leur activité au quotidien (CRM, ERP, Suite Office). Si chacune de ces applications permet de stocker, analyser, ou modifier certains types de données, ces dernières ne sont pas nécessairement compatibles entre elles. Plus encore, chaque service, équipe ou département peut utiliser un panel d’applications, parfois différents des autres entités de l’entreprise. La volumétrie de données collectées ou créées, l’absence d’uniformisation et la multiplicité des applications utilisées rendent difficile l’exploitation et l’analyse globale des données par les décisionnaires de l’entreprise, c’est là que la BI intervient.
2. Définition
La Business Intelligence (BI) désigne les moyens, outils et méthodes qui permettent de collecter, consolider, modéliser et restituer les données, matérielles ou immatérielles, d’une entreprise en vue d’offrir une aide à la décision et de permettre à un décideur d’avoir une vue d’ensemble de l’activité traitée.
2. La chaîne d’information décisionnelle et ses composantes
1. La chaîne d’information décisionnelle
La chaîne d’information décisionnelle comprend différentes phases :
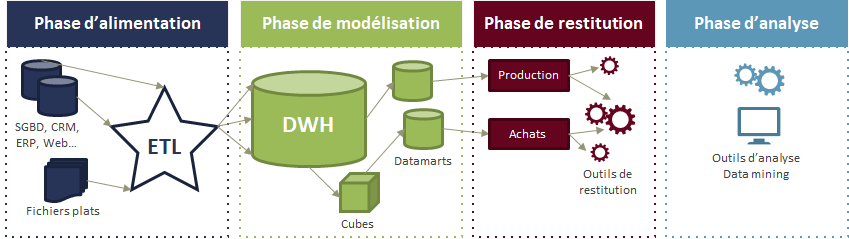
a. La phase d’alimentation
La phase d’alimentation consiste à détecter, sélectionner, extraire, transformer et charger dans un data warehouse (DWH, entrepôt de données) l’ensemble des données brutes issues des différentes sources de stockage de l’information (bases de données, fichiers plats, applications métier, etc.).
Cette phase est généralement réalisée grâce à un outil d’ETL (Extract, Transform, Load). Grâce à des connecteurs, l’ETL peut extraire un grand nombre de données de différents types, puis grâce à des transformateurs manipuler ces données pour les agréger et les rendre cohérentes entre elles. Nous verrons plus loin l’ensemble des fonctionnalités et des avantages des ETL.
b. La phase de modélisation
Une fois les données centralisées, la phase de modélisation consiste à stocker et structurer les données dans un espace unifié (le data warehouse) pour qu’elles soient disponibles pour un usage décisionnel. Cette phase est également réalisée grâce aux outils d’ETL via des connecteurs qui permettent l’écriture dans le data warehouse.
Les données peuvent à nouveau être filtrées et transformées pour assurer la cohérence de l’ensemble dans le data warehouse. Enfin, lors de cette phase les données stockées peuvent être prétraitées via des calculs ou des agrégations pour faciliter leur accès aux outils d’analyse.

c. La phase de restitution
La phase de restitution vise à mettre les données à la disposition des utilisateurs en prenant en compte leur profil et leur besoin métier. L’accès direct au data warehouse n’est pas autorisé puisque l’objectif est de segmenter et de diffuser les données collectées pour qu’elles soient cohérentes par rapport au profil de l’utilisateur et qu’elles soient simples à exploiter.
Lors de cette phase, de nouveaux calculs de données peuvent être effectués pour répondre aux besoins spécifiques des utilisateurs. Les outils de la phase de restitution sont multiples. Il peut s’agir d’outils de reporting, de portails d’accès à des tableaux de bords, d’outils de navigation dans des cubes OPAL (ou hypercubes) ou encore des outils de statistique.
d. La phase d’analyse
Dans la phase d’analyse, les utilisateurs finaux vont analyser les informations qui leur sont fournies. Habituellement, les données sont modélisées par des représentations basées sur des requêtes pour construire des tableaux de bord ou des rapports via des outils d’analyse décisionnelle (Power BI, Tableau, Qlikview, etc.).
L’objectif de cette phase est d’assister au mieux l’utilisateur pour qu’il puisse analyser les informations mises à sa disposition et prendre des décisions. Cela passe notamment par le contrôle d’accès aux rapports, la prise en charge des requêtes et la visualisation des résultats.
2. Focus sur les ETL (Extract, Transform, Load)
Comme présenté dans la chaîne d’information décisionnelle, les données traitées peuvent venir de nombreuses sources différentes (ERP, réseaux sociaux, CRM, logiciel d’emailing, objets connectés, etc.). L’accroissement constant des données collectées peut bien sûr être une opportunité pour les entreprises, à condition de savoir les exploiter.
Les outils d’ETL répondent à ce besoin grâce à :
- L’extraction de données issues des différentes sources d’information: Grâce à des connecteurs ou des APIs. Attention, on parle là de données existantes dans le SI de l’entreprise uniquement. Les ETL n’ont pas pour vocation à collecter de nouvelles données. De plus, il est possible d’utiliser des règles de gestion pour extraire une partie seulement des données.
- La transformation de ces données: La multitude des sources et des formats de données expliquent la difficulté pour les entreprises de les exploiter. L’ETL va transformer les données brutes collectées pour les nettoyer, conformer, standardiser, documenter, corriger et dupliquer au besoin. C’est une étape cruciale qui va permettre de rendre l’ensemble des données compatibles entre elles, et conformes au format cible (défini en fonction des cas d’usage que l’entreprise veut implémenter dans le DWH). En d’autres termes, cette opération consiste à agréger des tables de données entre elles pour créer des « super-tables ».
- Le chargement des données transformées dans le DWH : Une fois les données transformées, elles sont envoyées dans le DWH. Contrairement à un Data Lake, qui comprend un ensemble de données non agrégées/structurées, les données chargées dans le DWH sont organisées et structurées sur la base d’un langage commun.
Les principaux avantages liés à l’utilisation d’un ETL sont:
- Améliorer l’exploitation des données de l’entreprise, même dans des environnements complexes avec des sources de données multiples
- Couplé à un DWH, ils permettent d’avoir une vision exhaustive de l’ensemble des données dont l’entreprise dispose
- Améliorer l’efficacité des équipes IT, puisque les processus ETL alimentent automatiquement et en temps réel le DWH (moins de Scripts, codes à générer)
- Accroître l’agilité de l’architecture SI, puisque les ETL peuvent s’interfacer facilement à tout type de source de données
- Accroître la réactivité, grâce aux services annexes proposés avec les solutions d’ETL tels que l’envoi d’alertes pour prévenir les administrateurs en cas de problème
- Facilité de la prise en main des outils grâce à la représentation graphique des scripts utilisés
3. Focus sur les Data Warehouse et les Datamarts
Data Warehouse :
Lieu de stockage de toutes les données utilisées par le système d’information décisionnel. Il permet aux applications d’aide à la décision de bénéficier d’une source d’information homogène, commune, normalisée et fiable. De plus, le data warehouse assure une étanchéité entre le système opérationnel et le système décisionnel ; et donc réduit le risque que les outils décisionnels affectent les performances du système opérationnel en place. Le data warehouse doit suivre plusieurs principes clés :
- Être orienté métier: La structure du data warehouse doit être conçue en fonction des besoins des utilisateurs.
- Non volatile: Les données ne doivent jamais être réécrites ou supprimées ; elles sont statiques et les utilisateurs n’y ont accès qu’en lecture seule
- Intégré: Le data warehouse contient la plupart, voire l’ensemble des données de l’entreprise, et celles-ci doivent être fiables et cohérentes entre elles
- Historisé: Tous les ajouts/modifications dans le data warehouse doivent être enregistrés et datés
Datamart :
Petits « magasins » de données dont l’ensemble forme le datawarehouse. Ils sont un sous-ensemble du data warehouse et suivent donc les même principes clés. La différence entre les deux est que le datamart répond à un besoin métier plus spécifique que le data warehouse.
En matière de modélisation des Data warehouse, il existe principalement deux approches de pensées bien distinctes :
- La méthode Kimball : Approche dite ascendante dans laquelle on forme d’abord les datamarts en fonction des activités ou entités de l’entreprise. Il pourrait donc y avoir un datamart pour la finance, un pour les ventes et un autre pour les ressources humaines. L’information au sein de ces datamarts n’est pas standardisée. On conçoit ensuite le datawarehouse, qui est la combinaison de différents datamarts.
- La méthode Inmon : Approche dite descendante dans laquelle le datawarehouse est formé en premier avec l’ensemble des données disponibles de l’entreprise. Les datamart sont conçus dans un second temps en fonction des domaines d’activités ou des entités de l’entreprise.
En Parallèle de ses travaux sur la modélisation des data warehouse, Kimball a également proposé une approche de gestion de projet BI dans son ouvrage The Data Warehouse Lifecycle Toolkit (1998). Il propose trois concepts qui seront développés ultérieurement dans le cadre du cycle en V ou des méthodes agile.
4. Focus sur la restitution ou data visualisation (dataviz)
La data visualisation consiste à représenter visuellement des données brutes, en approche interactive, dans le but d’en simplifier leur manipulation, leur compréhension et leur maîtrise. Cette approche marque une volonté d’ouverture. La data (et son analyse) n’est plus un domaine ‘clos’, exclusivement réservée aux experts (data scientist, data analysts…), mais s’ouvre à des corps de métiers plus variés, à priori, moins initiés et plus éloignés de la complexité qui y est inhérente.
La production de volumes et la variété de données, toujours plus grandissantes à disposition des entreprises et une demande en analyse plus flexible et rapide, oblige une réflexion sur la stratégie de data management, et par conséquent des outils mis à disposition.
Les outils de dataviz participent à cette réflexion car ils ont pour ambition de simplifier l’accessibilité, la compréhension et l’interprétation des données arrivant en bout de chaine décisionnelle.
Une analyse en approche self-service est permise, l’utilisateur peut choisir l’angle sous lequel il veut étudier la donnée, une autonomie et une souplesse lui sont accordées sur les mesures, les dimensions et la formalisation des représentations (axés autour du visuel et de la schématisation des données), qu’il peut moduler à son aise.
En quelques mots, les outils de data visualisation permettent de :
- Centraliser l’affichage de la donnée en un seul et même endroit (accessibilité)
- Associer et croiser des données provenant de sources diverses
- Comprendre simplement et rapidement la donnée en lui conférant un ‘sens’
- Créer des tableaux de bords personnalisés et les partager
Dans le but de :
- Mesurer les performances et identifier les tendances remarquables
- Aider les décisionnaires dans leur orientation stratégique et favoriser les innovations
- Optimiser les organisations et le chiffre d’affaire
La data visualisation (restitution) est une composante essentielle dans la chaine d’information décisionnelle. Elle s’inscrit pleinement dans la stratégie d’une entreprise autour de la mise à disposition et l’analyse de la donnée. Les entreprises ayant une ambition réfléchie et pérenne autour de la donnée plébiscitent les outils de data visualisation.
Les éditeurs de logiciels manifestent leur engouement par la multiplication des offres de solutions de data visualisation, plus ou moins perfectionnées, sur le marché. Les éditeurs data/BI historiques (IBM, Microsoft, …), complètent aussi dorénavant, pour la plupart, leur offre par la proposition d’outils de data visualisation.
 Cette approche méthodologique, au-delà des outils, s’encre parfaitement dans l’ère du temps et participe à la démocratisation de la donnée.
Cette approche méthodologique, au-delà des outils, s’encre parfaitement dans l’ère du temps et participe à la démocratisation de la donnée.
3. Pourquoi parle-t-on de projet BI ?
1. Les spécificités du projet BI
Les projets BI sont la plupart du temps menés au sein des DSI des organisations par une équipe spécifique. La transversalité du projet et l’hétérogénéité des besoins sont deux caractéristiques d’un projet décisionnel. Si ces caractéristiques peuvent être vrai pour d’autres projets IT, elles le sont systématiquement pour des projets BI.
Transversalité et globalité du projet :
Une des spécificités d’un projet décisionnel est sa nature transverse à l’organisation. En effet, les domaines d’utilisation de la BI touchent tous les métiers de l’entreprise, de la finance à la logistique, en passant par les ventes et les ressources humaines. Pour garantir son succès et garantir la prise en compte de tous les besoins, un projet BI doit être mené globalement avec l’ensemble des métiers impactés. L’équipe projet doit donc avoir une très bonne connaissance des processus et des besoins métiers, et la collaboration entre le SI et le métier est une des clés de réussite des projets BI.
Hétérogénéité des besoins :
Contrairement à certains projets informatiques et comme vu précédemment, la BI impacte tous les métiers de l’entreprise. Or, chacun de ces métiers auront des besoins spécifiques en matière de données et d’informations. Une des difficultés des projets BI vient donc du fait que les besoins métiers sont nombreux et hétérogènes. Cela implique en terme de données une dépendance aux différentes sources externes que le chef de projet décisionnel devra adresser.
2. Les facteurs clés de succès d’un projet BI : la méthode GIMSI
Comme nous le verrons plus tard, la méthode n’est pas incompatible avec le Cycle en V ou l’Agilité. Il s’agit plutôt d’un cadre méthodologique qui formalise les conditions de réussite d’un projet BI. La signification de l’acronyme GIMSI est la suivante :
- Généralisation: la méthode peut être appliquée à différents domaines (administration, marketing, production) et par tous les types d’organisation (PME, association, Grande entreprise)
- Information : l’accès à la « bonne » information et le pilier de la prise de décision
- Méthode et Mesure : GIMSI est une méthode, dont le principe est la Mesure
- Système et Systémique : l’objectif de la méthode est de mettre en place un Système d’information décisionnel intégré dans le Système d’information de l’entreprise
- Individualité et Initiative : la méthode encourage l’autonomie des individus pour favoriser la prise d’initiative
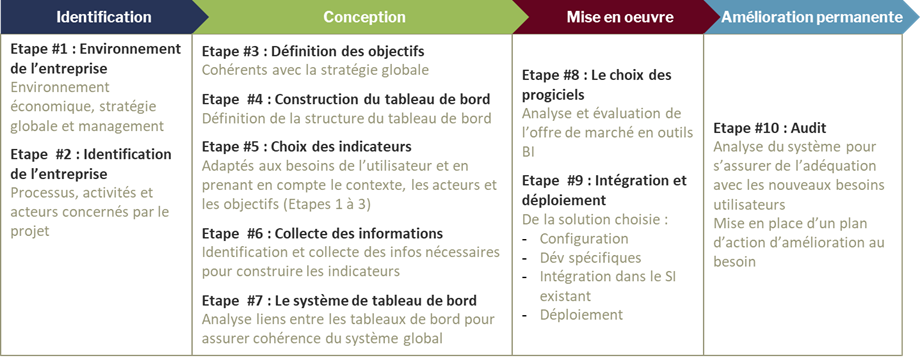
La méthode GIMSI s’articule autour de 4 phases :
1. Identification : Quel est le contexte?
Lors de cette phase, on étudie :
- L’environnement externe de l’entreprise : environnement concurrentiel, politique, économie, technologie
- L’environnement interne : stratégie d’entreprise, organisation, quels processus ou activités on veut inclure dans le projet (logistique, vente, RH, etc.)
2. Conception : Que faut-il faire ?
Lors de cette phase, on réalise toutes les activités de conception de la solution :
- Les objectifs du projet BI : quel est le but du projet, quels sont les bénéfices attendus
- La structure des informations : quelles informations seront disponibles pour chaque processus sélectionné et sous quel format ?
- Les données nécessaires : identification et collecte des données nécessaires pour fournir les informations définies précédemment
- La cohérence globale : est-ce que la conception globale permet d’atteindre les objectifs fixés? Est-ce qu’il y a des redondances dans les données collectées ?
3. Mise en oeuvre : Comment le faire?
Lors de cette phase, on met en oeuvre la solution, avec :
- Le choix du logiciel BI pour supporter le projet
- Le déploiement du logiciel dans l’entreprise
4. Amélioration permanente : Est-ce que le système correspond toujours aux attentes?
Suite au déploiement, on analyse régulièrement le système et les nouveaux besoins des utilisateurs pour s’assurer que la solution mise en place permet de répondre à ces nouveaux besoins.
4. Pour conclure
La Business Intelligence (BI) ou informatique décisionnelle apporte à l’entreprise des outils pour leur faciliter la prise de décision stratégique ou opérationnelle. Elle utilise l’analyse des données comme principe de base.
L’ETL permet d’extraire, de modifier et de charger les données. Ces données sont ensuite stockées dans un data warehouse (entrepôt de données) qui les présente de manière intelligente. C’est ce qu’on appelle la chaîne d’information décisionnelle.
Les projets décisionnels se caractérisent par leur transversalité car ils concernent plusieurs métiers et départements de l’entreprise. Les données utilisées sont souvent hétérogènes en fonction des besoins utilisateurs ce qui implique une dépendance aux sources externes.
L’Offre conseil « Data Solution » de HeadMind Partners permet d’accompagner ses clients dans leur transformation digitale autour du décisionnel. Nos consultants mettent à disposition leur expertise pour la mise en place des outils BI adaptés à l’environnement et aux problématiques métiers de nos clients.
Article écrit par Anjana LARUE, Clody CORDETTE, Marc CHATELLIER et Ajaz GHULAM, membres de la BCOM Data BI chez HeadMind Partners Digital.
Sources
- Site Web: Eiden, Florian « Gestion de Projet Décisionnel – Méthodes Agiles ou Cycle en V ?». La BI ça vous gagne ! .2012. https://fleid.net/tag/cycle-en-v/
- Site Web: Eiden, Florian « Gestion de projet décisionnel : gardez vos utilisateurs proches de vous! La BI ça vous gagne ! .2012. https://fleid.net/2011/12/20/gestion-de-projet-decisionnel-gardez-vos-utilisateurs-proches-de-vous/
- Site Web: Boyer, Clément « Le cycle en V » SupInfo International University .2017. https://www.supinfo.com/articles/single/6278-cycle-v
- Cours: RIGAUD, Lionel. Gestion de projet BI. Option Business Intelligence, CY TECH (EISTI), 2012
- Livre: Kimball, Ralph « The Data Warehouse Lifecycle Toolkit » 1998
- Site Web: Deltil, E., & Pereira, G. « BI – Business Intelligence : Présentation » Université de Marne La Vallée. 2017. https://www-igm.univ-mlv.fr/~dr/XPOSE2006/DELTIL_PEREIRA/presentation.html#besoin
- Site Web: Cartelis. « Comparatif complet des logiciels ETL : Cloud vs On-Premise vs Open Source » Cartelis. 2018. https://www.cartelis.com/blog/comparatif-logiciels-etl/
- Site Web: Ecole supérieure d’Informatique Supinfo. « Comprendre les étapes d’un processus BI » Supinfo. 2017. https://www.supinfo.com/articles/single/3548-comprendre-etapes-processus-bi
- Site Web: Fernandez, A. « La méthode GIMSI » Piloter.org. 2018. https://www.piloter.org/mesurer/methode/fondamentaux_gimsi.htm
- Site Web: Wikiversité. « Gestion de projet stratégique : Projet décisionnel » Wikiversité. https://fr.wikiversity.org/wiki/Gestion_de_projet_strat%C3%A9gique/Projet_d%C3%A9cisionnel
- Site Web: Lau, S. & Sabatier, J. « Business Intelligence : Place de la BI et pilotage des projets décisionnels dans les grandes organisations françaises » CIGREF. 2009. https://www.celge.fr/wp-content/uploads/2015/09/Business_Intelligence_CIGREF_2009.pdf
- Site Web: Sodifrance. « Les étapes et notions d’un projet BI » Sodifrance. 2009. https://blog.sodifrance.fr/les-etapes-et-notions-dun-projet-bi-2/
- Site Web: Deltil, E., & Pereira, G. « BI – Business Intelligence : Les étapes du processus » Université de Marne La Vallée. 2017. https://www-igm.univ-mlv.fr/~dr/XPOSE2006/DELTIL_PEREIRA/processus.html#collecte
- Site Web: Lecomte, S. « Projet BI : 4 étapes à suivre pour réussir » Alphalyr. 2019. https://alphalyr.fr/blog/projet-bi-etapes-pour-reussir/
- Site Web: Cartelis. « Architecture Data Warehouse – Approches traditionnelles vs Cloud » Cartelis. 2018. https://www.cartelis.com/blog/architecture-data-warehouse/
- Site Web: Tehreem, N. « Concepts d’entrepôt de données : approche Kimball vs Inmon » Astera. 2020. https://www.astera.com/fr/type/blog/data-warehouse-concepts/
Derniers articles
- Réseaux sociaux et connaissance client

- Analyse des solutions de sécurité réseau et leur complémentarité

- Bonnes pratiques de sécurité des voyages

- ISO 27001 et ISO 27002, une nouvelle version majeure pour des changements majeurs

- DEEPFAKE : Le nouveau casse-tête des méthodes d’authentification
